Design patters is something that you will need to get familiar with as a programmer who works with object oriented languages. And this is primarily because they represent well-defined solutions to common problems. So, instead of thinking through all the details of your solution, you can simply check if any of the existing design patterns can be used instead. You won’t have to reinvent the wheel.
Design patterns are not to be confused with software design. While software design refers to the process that is done before any code is even written, design patterns are ways of structuring your code while you are already writing it. If it’s software design, rather than design patterns, that you are interested in, Galaxy Weblinks has published a great article on software design tips. But if it’s design patterns that you are interested in, let’s continue.
The main problem with design patterns is that they are not necessarily easy to learn. Many developers, especially the ones who don’t have a lot of software-building experience, struggle with them. I have even seen people who, while struggling to grasp design patterns, say that it’s some kind of conspiracy to make the process of software development harder than it would have been!
Of course, I wouldn’t hire those people, but I do agree that design patters can be difficult to grasp. And this, I believe, is mainly due to the way they are commonly taught.
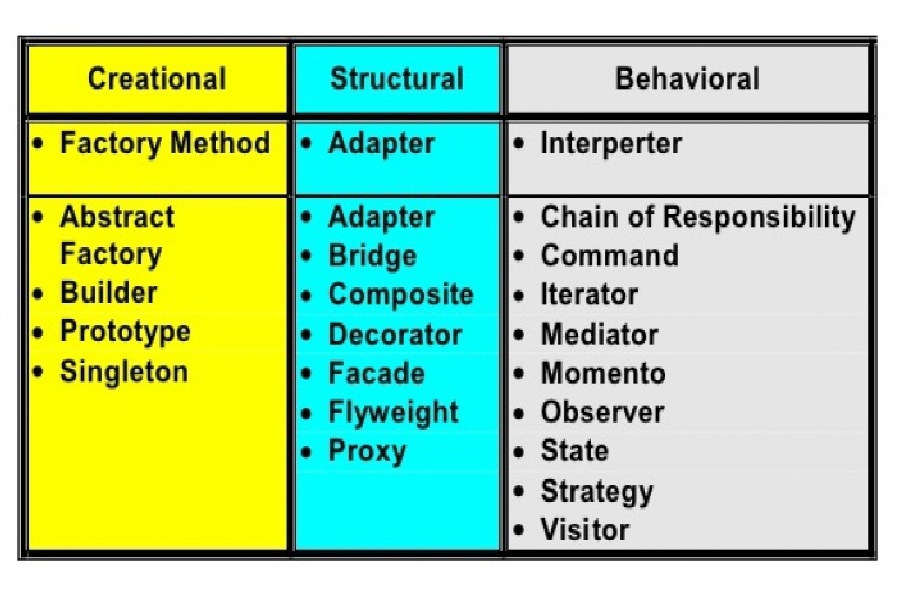
Normally, when you open any of the learning material on design patterns, you are first presented with the design pattern categories. You learn that design patterns can be creational, structural and behavioral. And then you go into each category and start learning the actual design patterns. Only then you are told how each design pattern is actually useful.
But if you have never knew anything about design patterns before, you may wonder, how knowing the difference between creational and behavioral patters will benefit you? And how do you even select the right pattern for your new code? Which patterns are more important than others? Perhaps, these is where the conspiracy theories about the design patterns come from. But there is a much better way of learning design patterns than this.
It is a common misconception that the process of learning primarily consists of memorizing new information. To make the process of learning much more effective, you need to treat it as building new associations to the concepts that you already know. Essentially, it would be more about expanding what you already know, and then, once you internalize the knew knowledge, expanding it further.
And this system can be easily applied to learning design patterns. Instead of first learning the design patterns categories, then spending time memorizing the actual patterns and then practicing with each of them until you have an encyclopedic knowledge of all of them and are able to choose the right one in every situation, you can change the learning steps to the following:
- Learn what are the common problems that the design patterns can address.
- Learn the names of the design patterns that can address each of these problems.
- Learn the reasons why you would need to use those particular design patterns.
- Learn how those design patterns actually work.
- Learn the difference between design pattern categories.
- Learn which category each design pattern belongs in.
Depending on your experience as a developer, you probably have encountered a number of common problems that design patterns were made to solve. Even if you haven’t encountered some of them, you will still be able to easily relate to them. And this is why getting familiar with specific types of problems you would need design patterns for would be the first step in learning design patterns.
After that, you would need to associate the actual design patterns with the problem. You won’t have to know how those design patterns work yet. Knowing its name would suffice. All you need to memorize is that for a problem X, there is a pattern Y. This shouldn’t be difficult to memorize at all, as there is not an overwhelming amount of information to memorize.
Then you would need to learn why those design patterns are the best solutions to that problem. When you understand it, you won’t over-engineer your code, blindly throwing design patterns everywhere, regardless of whether they are relevant or not. Plus you need to understand what would the benefits of using the design patterns will be, so you won’t just think that you are only using them because your boss wants you to.
The next step would be to actually find out what a given design pattern does. This is where you will see for yourself all the benefits of using it. And, after all, design patterns are useless unless you know how to use them.
The last two steps are, pretty much, optional. You will only need to know the differences between design pattern categories and which design patterns belong in which category in case you will be asked these questions during a job interview. Knowing how to use, let’s say, an abstract factory and being familiar with what kind of problems abstract factory was made to solve is way more important than knowing that abstract factory is a creational design pattern rather than structural. On the other hand, if you have already progressed that far, learning these remaining things will be easy, so you might as well do it.
So, without further ado, let’s list the common problems that design patterns were made to solve and take it from there. i’ll have to warn you though that it’s a very long post.
Problem 1 – You don’t know ahead of time what exact type and its dependencies your code should work with
Description of the problem
Imagine that you have a code that uses a particular object type. The code that uses this object only needs to know the signatures of accessible methods and properties of the object. It doesn’t care about the implementation details. Therefore, using an interface that represents the object rather than a concrete implementation of the actual object is desirable.
If you know what concrete implementation your application will be using ahead of time, you can simply apply dependency inversion principle along with some simple dependency injection. In this case, you will know that it’s always a particular implementation of the interface that will be used throughout your working code and you will only replace it with mocked objects for unit testing. But what if the concrete implementation of the interface needs to be chosen dynamically based on runtime conditions? Or what if the shape of the object needs to be defined based on input parameters in the actual place where the object is about to be used? In either of these cases, the dependency injection approach wouldn’t work.
Let’s look at an example of this. Imagine that you are building an application that can play audio. The application should be able to work on both Windows and Linux. And inside of it, you have an interface called IPlayer that has standard methods that an audio player would have, such as Play(), Pause() and Stop(). It is the implementation of this interface that actually interacts with operating system and plays the audio.
The problem is that Windows and Linux have completely different audio architectures; therefore you cannot just have a single concrete implementation of IPlayer interface that would work on both operating systems. And you won’t know ahead of time what operating system your application will run on.
Suitable design patterns
Factory Method
Factory method is a method that returns a type of object that implements a particular interface. This method belongs in a creator object that manages the lifecycle of the object that is to be returned.
Normally, you would have several variations of the creator object, each returning a specific implementation of the object that you want. You would instantiate a specific variation of the creator object based on a specific condition and would them call its factory method to obtain the implementation of the actual object.
In our example above, you would have one version of the creator object that returns a Windows implementation of IPlayer and another version that returns its Linux implementation. The creator object will also be responsible for initializing all dependencies that your IPlayer implementation needs. Some code block in your application will check which operating system it runs on and will initialize the corresponding version of the creator object.
Why would you want to use Factory Method
Why bother using factory method, if you can just initialize any objects directly? Well, here is why:
- Good use of single responsibility principle. The creator object is solely responsible for creating only one specific implementation type of the end-object and nothing else.
- The pattern has been prescribed in such a way that it makes it easy to extend the functionality of the end-object and not violate open-closed principle.
- Easy to write unit tests, as creational logic will be separated from the conditional logic.
Detailed description of Factory Method
For all design patterns, I have used two authoritative online sources – Source Making and Refactoring Guru. Each of the links will take you to a detailed description of the design pattern, including examples of its implementation in several programming languages.
Factory method on Source Making
Factory method on Refactoring Guru
Abstract Factory
Abstract factory is a design pattern that uses multiple factory methods inside of the creator object, so you can create a whole family of related objects based on a particular conditions instead of just one object.
Let’s change the above example slightly. Imagine that our app needs to be able to either play audio or video, so you will need to implement two separate interfaces – IAudioPlayer and IVideoPlayer. Once again, it must work on either Linux or Windows.
In this case, your abstract factory will have a separate method to return an implementation of IAudioPlayer and a separate method to return an implementation of IVideoPlayer. You will have a version of the factory that is specific to Windows and another version that is specific to Linux.
It’s known as abstract factory because it either implements an interface or extends an abstract class. It is then up to the concrete implementation to create concrete implementations of the output objects that together are relevant to a specific condition.
Why would you want to use Abstract Factory
- As it uses factory method, all of its benefits will apply
- It guarantees that concrete implementations of different objects are always compatible with each other
Detailed description of Abstract Factory
Abstract factory on Source Making
Abstract factory on Refactoring Guru
Builder
Builder design pattern is similar to factory method, but instead of just returning a concrete implementation of an object all at once, it builds the object step-by-step.
Let’s go back to our OS-independent app that plays audio. In the factory method example, we had a concrete implementation of the IPlayer interface for each operating system. However, instead of doing this, we may have a single concrete implementation of the interface that would act as a shell object. Let’s call it Player. It will be this type that gets produced in all scenarios, but the concrete parameters and dependencies will be injected into it based on what kind of operating system it’s running on.
For example, both Linux and Windows allow you to play audio and manipulate its volume via the command line. On Linux, it will be Bash Terminal. On Windows, it will be either cmd or PowerShell.
The principles are similar. In both cases, you would be typing commands. But the exact commands will be completely different. Plus there are likely to be separate commands for playing audio files and for manipulating audio volumes.
So, in this case, our Player class will simply delegate the playback of audios to operating system components that are accessible via a command line interface. It’s only the actual commands that will be different.
And this is where a builder design pattern comes into play.
Builder consist of two main components – builder and director. Builder is a class that returns a specific object type. But it also has a number of methods that modify this object type before it gets returned. Director is a class that has a number of methods, each of which accepts a builder class, calls methods on it in a specific way and gets the builder to return the finished object.
So, in our case, imagine that our builder class for the Player object (which we will call PlayerBuilder) has the following methods: SetPlaybackInterface(<interface instance>), SetAudioVolumeInterface(<interface instance>) and BuildPlayer(). When we instantiate our PlayerBuilder class, we instantiate a private instance of Player class inside of it. Then, by executing SetPlaybackInterface() and SetAudioVolumeInterface() methods, we dynamically add the required dependencies to it. And finally, by executing BuildPlayer() method, we are returning a complete instance of Player object.
In this case, our director class will have two methods, both of which accept PlayerBuilder as the parameter: BuildWindowsPlayer() and BuildLinuxPlayer(). Both of these methods will call all the methods on the PlayerBuilder class in the same order and both will return an instance of Player class. But in the first case, the methods will be called with Windows-specific implementation of the command line interfaces, while in the second case it will be with the ones that are specific to Linux.
However, unlike either abstract factory or factory method, builder is not only used to build an object the implementation details of which can only be made known at runtime. It is also used to gradually build complex objects.
For example, .NET has inbuilt StringBuilder class in its core System library. This class is used for building strings from several sub-strings, so you don’t have to just keep replacing an immutable string in the same variable.
Why would you want to use Builder
- Good use of single responsibility principle. Each builder method has its own very specific role and there is a single method on the director class per each condition.
- Easy to write unit tests. This is facilitated by single responsibility principle.
- No need to have different versions of a class if only some of its implementation details may change in different circumstances.
- Because an object can be built step-by-step, it is the best design pattern to decide what the object will be if you have to adjust its properties one by one by multiple steps of a conditional logic.
- You can reuse the same code for different representations of the final object.
Detailed description of Builder
Problem 2 – You need to make several exact copies of a complex object
Description of the problem
Imagine that you have an object that you need to copy multiple times. Because it’s not a primitive type, you cannot just copy the value of the whole thing into a new variable of the same type. Instead, you would need to instantiate a new object of this type and then copy the value of every field from the original object instance.
That would be fine for simple objects with a relatively small number of fields that contain primitive types, such as integers and Booleans. But what if you are dealing with complex objects with many fields, some of which contain other objects?
In this case, you would need to write a complex code to make a copy of an object. This way of doing things is prone to errors. Plus, you will have no access to private members of the object, so you may not necessarily end up with an exact copy and suffer some undesirable side-effects as the result.
Suitable design patterns
Prototype
Prototype is a design patter that was created specifically for this problem.
If you have a complex object that is meant to be copied often, you can make it cloneable. And this is exactly what this design pattern enables you to do.
You would have an interface with a method that produces an instance of an object that implements this interface. Usually, such method will be called clone(). And, if you want to make your object cloneable, you just implement this interface when you define the object type.
Inside this method, you will still need to copy the value of every field into the output object. However, this time, you will only have a single place in the entire code to do it in – the object itself. So, it will be easier to have a close look at it and consider all edge cases. Likewise, you will have full access to the private members of the object, so your copy will be exact.
Why would you want to use Prototype
- All code to copy complex objects is located in one place
- You can copy private members of the object
- Any code that needs to generate a copy of the object will only need to call clone() method without having to worry about the details of the cloning process
Detailed description of Prototype
Problem 3 – You need to use several instances of an object while keeping your code performant
Description of the problem
Imagine that you have a need to use many similar objects in your application. Perhaps, you are building a distributed application based on microservices architecture and each of these objects represents a unique connection to one of your services. Or maybe you are interacting with multiple database entries.
In this situation, purely using inbuilt language features will probably be problematic. You will need to instantiate every single one of these objects. Once the object is out of scope, your runtime will need to get rid of it to free up the memory. Once you need a similar object again, you will instantiate it again. And so on.
If you follow this approach, you will probably experience a performance hit. Instantiating a new object each time you need to use it is a relatively expensive process. The runtime will need to allocate memory for it and populate those chunks of memory with new values.
If you are using similar objects in different parts of the application, you will be required to allocate sufficient memory to each instance of the object. And that may become quite a lot of memory if you need to use many of such instances.
Likewise, when you are instantiating a new object, there is always a cost associated with running the constructor of the object’s data type. The more complex constructor logic is, the bigger performance hit you will get.
Finally, when you are no longer using an instance of the object and it gets out of scope, there will be a performance cost associated with garbage collection. Remember that the memory will not be freed straight away. It will still be occupied until the garbage collector has found your object and identified that it is no longer being referenced anywhere.
The latter, of course, doesn’t apply to the languages that don’t have in-built garbage collector. However, in this case, you will have to free the memory yourself if you don’t want to introduce a memory leak. So, if you are using one of such languages, you will have an additional issue in your code to worry about.
Suitable design patterns
Object pool
Object pool is a pattern that allows you to reuse the same objects, so you won’t have to keep instantiating them every time.
You have a single object that stores multiple instances of instantiated objects of a specific type. If any of these objects aren’t being used, they are stored inside the pool. Once something in the code requests an object, it becomes unavailable to any other parts of the code. Once the caller has finished with the object, it gets returned to the pool, so it can be reused by other callers.
Initially, you may still need to instantiate objects in the pool. However, when your pool grows to a reasonable size, you will be instantiating new objects less and less, as there will be a greater chance to find objects in it that have already been released by their respective callers.
To ensure that the pool doesn’t grow too big, there will be a property that will limit its size. Likewise, a mechanism inside of it will determine which object instances to get rid of and which ones to keep. For example, you don’t need an object pool with 1,000 object instances if your application will only ever use 10.
Why would you want to use Object Pool
- Objects are being reused, so you will not get any performance penalty associated with instantiating new objects
- Object pool maintains its size as needed, so you will not end up with way more object instances than you would ever expect to use
Detailed description of Object Pool
Flyweight
This design pattern allows multiple objects to share parts of their state. So, for example, if you have a thousand objects, all of which currently have the same attribute values, these set of attributes will be moved to a separate object and all thousand instances will be referring to the same instance of it.
This allows you to store way more objects in the memory than you would have been able to otherwise. In the case above, instead of having a thousand instances of a particular object type with all their property values that take a lot of memory, you would have thousand basic skeleton objects, each of which occupies only a tiny amount of space and you will have all the property values stored in the memory only once.
One disadvantage of flyweight, however, is that it makes your code complicated. You will need to decide which parts of the state are shared and which aren’t. Also, you will need to do some thinking on the best way of changing the state once it becomes irrelevant to any specific instance of an object.
Based on this, it’s recommended to only use flyweight if you absolutely must support systems where the performance of your code would very noticeably decrease otherwise.
Why would you want to use Flyweight
- Squeezing way more information into memory than you would have been able to otherwise
Detailed description of Flyweight
Prototype
Prototype, which we have already covered, can also help to solve this problem. However, unlike object pool, it will not give you any performance benefits.
What prototype will give you in this situation is the ability to create many similar objects without having to go through a complex process of defining their field values each time.
For example, you may have a service that communicates with several instances of the same microservice and each of this instances is presented by an object in the code. Let’s say that all microservices are accessed by the same IP address, but a different port. And the rest of connection parameters are also identical.
In this case, your configuration file may contain all shared connection parameters. And you will only have to go through the configuration once to create the prototype object. After that, to create any new connection objects, all you’ll have to do is clone the existing one and change the port number value accordingly.
Problem 4 – You need to use the same single instance of an object throughout your application
Description of the problem
Imagine that you have a need to use exactly the same object throughout your entire application, regardless of whether the classes that use it can communicate directly with each other or not. One thing you can do is instantiate it in one place and then pass the instance to every single class.
This will work, but it’s less than desirable. It means that you will have to write a lot of extra code that will be hard to read and maintain.
Plus, there is nothing that would stop passing a different object reference into a class that uses it, especially if a developer that is currently working on the code doesn’t know that the original intention was to keep the reference the same across the board. This will probably introduce some bugs.
Suitable design patterns
Singleton
With this design pattern, the class that you want to have a single instance of will have a static method that will return an instance of this class. Behind the scene, this method will call a private constructor the first time you call it, so the class will be instantiated only once. If you call this method again, then the same instance will be returned as was instantiated before.
Otherwise, the class will have no public constructor, so it will not be possible to create a new instance of it by any external code. This will guarantee that, no matter where you are calling the static method from, exactly the same instance of the class will be returned.
Why would you want to use Singleton
- Being able to use the same instance of an object in any part of your application without explicitly passing an instantiated object
- It will prevent you from creating more than one instance of a particular type
Detailed description of Singleton
Object Pool
We have already covered object pool as a design patter primarily intended for managing multiple instances of the same object type without incurring much of performance penalty. However, to be fully effective, object pool also needs to be a singleton.
So, in the nutshell, to make the most of object pool, the class that acts as an object pool must also implement the singleton design pattern.
Problem 5 – you are working with third party components that aren’t compatible with your code
Description of the problem
Imagine that you are working with a third party library that returns data in a specific format. The problem is, however, that this is not the data format that the rest of your application works with.
For example, your code may only be working with JSON, while the third party library only delivers data as XML. In this situation, the last thing that you would want to do is rewrite the rest of your code to make it compatible with XML, especially if you don’t expect anything other than this library to use XML.
There is also another variety of this problem that you may encounter. Once again, you are dealing with a third party library, but this time, it’s accessible interface is written differently from how the set of related functionality is written in your application. If this third party library is meant to be able to replace your own components, ideally it should use the same signatures on its accessible members as your own classes are using. Once again, in this case, last thing you want to do is include special cases into what was meant to be a generic code.
It doesn’t necessarily have to be a third party library though. It could be your own legacy code that was written a while ago, when either a different philosophy was implemented or modern best practices weren’t properly followed. In this case, you cannot just change the legacy components, as it has already been extensively tested and many other components within the system rely on it.
All these examples have one thing in common – you need to work with something that is structurally different from the rest of your code, but making changes to your own code is not desirable.
Suitable design patterns
Adapter
You can think of adapter as a wrapper class for whatever component you would want to use in your code that is currently incompatible with it. The adapter class will be accessible by using exactly the same components in your code use, while internally it will be calling methods on the external component and transfer all the data it gets from it into a format that is compatible with the rest of your code.
Basically, adapter class in analogous to a real-life physical adapter, such as an electric socket plug adapter. As you may know, US, UK and continental Europe use different electric sockets. So if you are travelling from US to Europe, you won’t be able to just plug your electronic devices in. You will have to purchase an adapter that has the same input configuration as a wall socket in the US, but has the same output pin configuration as European socket plug.
Why would you use Adapter
- Adapter allows you to isolate interface conversion functionality to only a single place in your code
- Open-closed principle is enforced
- The access point into the immutable external component is standardized along with the rest of your code
Detailed description of Adapter
Problem 6 – you need to add new functionality to existing objects, but you can’t change them
Description of the problem
This problem relates to the previous one, but has a subtle difference.
Imagine that you have a similar situation. There is either some third party library or your own legacy code that you need to use. And you can’t change the components that you are about to use. However, this time, you are perfectly fine with using the components as they are, because they are already fully compatible with your code.
This time, however, the problem lies in the ability to extend those components. If you need to add a new set of functionality to them, you can’t. And this is because you either don’t have access to the internal code of those components, or simply aren’t allowed to make this change.
Or maybe the external component is not fully compatible with your code, so you will need to both make it compatible and then extend it. However, making the component compatible with your code is a different problem that we have already covered. The specific problem that we are looking at now is the ability to extend the behavior of the objects that you can’t modify directly.
Suitable design patterns
Decorator
Decorator is a design patter that is similar to adapter. Just like with adapter, decorator class acts as a wrapper around the original object. However, instead of changing the interface of the original object, it enhances the existing interface.
So, when you apply decorator design patter, anything in your code that could previously use the original object would still be able to use the decorator class in its place. And this is precisely because the original structure of the interface was left intact. It was simply expanded with new members.
Why would you use Decorator
- It will give you the ability to easily add functionality to those objects that you can’t modify directly
- Open-closed principle is enforced
- You can use it recursively by applying additional decorators on top of the existing ones
- You can dynamically add responsibilities to an object at runtime
- Single responsibility principle is applied well, as each decorator can be made responsible for only a single additional functionality
Detailed description of Decorator
Problem 7 – you are dealing with a complex set of classes that you need to access
Description of the problem
Imagine that you are dealing with a whole range of complex classes, all of which you would need to access from a single layer of your application. It could be, for example, code that has been auto-generated from WSDL definition. Or it could be some manually written code, where different classes retrieve data from different data sources.
Because you will need to access all of these classes from the same layer within your application, using those classes directly would probably not be the most optimal thing to do. You would need to add references to all of these classes to the other system components that need to access them.
This is especially problematic with auto-generated classes, as you won’t be able to easily create abstractions for them. So, you will either have to manually edit auto-generated code (which isn’t a good idea), or pass the concrete classes as references into the components that need them (which is also a bad idea and a clear violation of dependency inversion principle).
The problem will become even more apparent if those complex classes are meant to be updated fairly frequently.
Suitable design patterns
Facade
Facade is a class that controls access to a set of complex objects and makes it simple. Most often, just like an adapter, it would change the access interface into these classes. However, unlike adapter, it will usually be a wrapper around several of such classes. Or, unlike adapter, it may be responsible for a diverse set of operations between a number of moving system parts rather than just converting one type of call to another type.
Direct interaction with those complex classes is happening only inside the facade class, so the other system components are completely shielded away from it. All that the client class will be concerned about is calling the specific methods on the facade. Client doesn’t care how facade delivers what it needs; it only cares that facade does the job that is expected of it.
And when any of the above mentioned components needs to be updated, the update in the logic will only need to happen inside the facade, which will prevent the other parts of the system from having bugs unintentionally introduced into them by forgetting to update the logic.
Why would you use Facade
- A convenient way of simplifying access to a complex subset of the system
- All other application components are shielded away from having to interact with a complex logic
- Since all the code that interacts with a complex subsystem is located in one place, its easier not to miss updates to the logic is any of the subsystem components get updated
Detailed description of Facade
Proxy
Proxy is not suitable for wrapping a complex logic into a simple accessible interface, but it’s still suitable for dealing with subsystem components that are not easy to work with directly.
For example, you may be in a situation where you would only need data from a particular service on rare occasions. If this data takes a long time to obtain and it rarely changes, proxy can be used to access this data once and store it in memory until it changes.
Or you may have a situation where you would need to restrict access to a particular service based either on a specific outcome of business logic or the roles that the user is assigned to. In this case, proxy would conduct this check before the actual service is accessed.
So, essentially, proxy is nothing other than a wrapper around a class that has exactly the same access interface as the original class, so both classes are interchangeable. Proxy class is there to restrict access to the original class. It can also be used to implement any pre-processing of the request if it’s needed before the original class can be accessed and implement additional access rules that cannot be added to the original class directly.
Why would you use Proxy
- You can abstract away all complex implementation details of accessing a particular class
- You can apply additional request validation before you access a particular class
- You can get it to only access the actual class when it’s necessary, which would positively affect the performance
Detailed description of Proxy
Problem 8 – you are building an application where user interface and the business logic are developed separately
Description of the problem
You have two separate teams working on the application. One team consists of front-end specialists, who are capable of making a really beautiful user interface. The other team aren’t as good at building user interfaces, but it’s really good at writing business logic.
Also, what you intend to do is make the user interface compatible with several different types of back-end. Perhaps, the user interface is built by using a technology that can run on any operating systems, such as Electron, while there are different versions of back-end components available for different operating systems.
Suitable design patterns
Bridge
Bridge is the design pattern that was developed specifically to solve this problem. It is a way of developing two parts of application independently of each other.
When bridge is used, the user interface part of the application is known as interface, while the back-end business logic part of the application is known as implementation. This is not to be confused with interface and implementation as object oriented programming concepts. In this case, both user interface and the back end would have various interfaces and concrete classes that implement them. So, what is known as interface doesn’t only consist of interfaces and what is known as implementation doesn’t exclusively consist of concrete classes.
Usually, bridge is designed up-front and developers agree how interface and implementation are to communicate with one another. After that, both of these components can be developed independently. One team will focus on business logic, while another team will focus on usability.
With this design, implementations can be swapped. So, as long as the access points of the implementation are what interface expects them to be, any implementation can be used.
Using different implementations for different operating systems or data storage technologies is one of the examples. However, you can also develop a very simple implementation with faked data for the sole purpose of testing the user interface.
Why would you use Bridge
- You can develop user interface and business logic independently
- You can easily plug the user interface to a different back-end with the same access points signatures
- Those who are working on the user interface don’t have to know the implementation details of the business logic
- Open-closed principle is enforced
- Single responsibility principle is well implemented
Detailed description of Bridge
Facade
Although less suitable than bridge, Facade can be used in certain circumstances.
For example, imagine that you will have to access the back-end of the app via WSDL, which would have some auto-generated code associated with it. This is where a facade class would be helpful, as it will abstract away all complex implementation details of this communication mechanism.
But if you don’t have to deal with the complex contracts between front-end and back-end components, then facade is not the most useful design pattern to solve this specific problem.
Proxy
Proxy design pattern is useful if your application is relatively simple.
Essentially, you may have some back-end classes and their simplified representations that the UI components will interact with. In this case, you may have interchangeable implementations of back-end classes that the same proxies can deal with.
Problem 9 – you are building a complex structure where an object of a particular type can contain other objects of the same type
Description of the problem
Imagine that you need to construct a structure where objects need to act as containers to similar objects. It could be that you are building a tree-like data structure. Or perhaps you are building a representation of a file storage system where folders can contain files and other folders.
Suitable design patterns
Composite
Composite is a design pattern that allows you to build tree-like structures in an efficient way.
There are two types of classes involved – a leaf class and a composite class. Both of these classes implement the same interface; however a composite class would have more methods on it.
A leaf class is the simplest class in the structure. It cannot have any additional members. A composite class, on the other hand, can have a collection of members, which can be absolutely any type that implements the interface that both leaf and composite classes implement.
Essentially, a composite class can contain other instances of composite class and leaf instances. Therefore, a composite class would have methods that would allow it to manipulate the internal collection of its children, such as Add(), Remove(), etc.
The best analogy would be a file storage structure. You can think of files as leaf objects and folders as composite objects. A folder can contain other folders and files, while a file is a stand-alone object that cannot contain any other objects.
Why would you use Composite
- Really easy way of building any tree-like structures
- Members of the tree structures are easily distinguishable
Detailed description of Composite
Builder
Builder is not specifically intended for solving this problem, but this design pattern is often the easiest way to construct a composite object.
Builder is not only used for gradually constructing a singular object. For example, in C#, StringBuilder class from the core library is used for building strings of arbitrary length.
In a similar manner, builder can be used for building a composite object of any arbitrary shape.
Problem 10 – you have a complex conditional logic in your code
Description of the problem
So, you need to implement either a switch statement with several cases or an if-else logic with several conditions.
A traditional way of dealing with this is just to implement specific code under each condition. However, if you are dealing with a complex conditional logic or a complex code, your code will become harder to read and maintain.
If you have this conditional logic inside a single method, it will probably become quite difficult to write unit tests for this method. And your code will probably violate SOLID principles, as the method will have more than one responsibility. It will be responsible for both making the conditional decisions and executing different types of logic based on those decisions. You may end up having as many responsibilities inside this method as there are conditions in your statement!
Suitable design patterns
Strategy
Strategy is a design pattern where you have a container object, usually referred to as context, that contains a specific interface inside of it. Strategy is any class that implements this interface.
The exact implementation of strategy object inside the context object is assigned dynamically. So, context object allows you to replace the exact implementation of the strategy object at any time.
Strategy object would usually have one main method that is defined on the interface and the context object will have a wrapper method with a similar signature that will call this method on the current strategy implementation.
So, what you would normally do is write several strategy implementations, each of which would contain it’s own version of the main method. Then, when you need to have any multi-condition logic, all you will do under each condition is pass a particular implementation of the strategy into the context class and at the end, you just execute the main method on the context.
So, if you do this, all that your method with the conditional logic will be responsible for is deciding which strategy to pass into the context class. And it will be trivial to validate this behavior with unit tests. And then, each strategy implementation will be solely responsible for its own specific version of the logic that is to be executed, which is also easy to read and write unit tests against.
Why would you use Strategy
- Really easy way of isolating specific conditional behavior into its own method
- Helps to enforce single responsibility principle by leaving the code with the conditional statements for being solely responsible for outlining the conditions
- It becomes easy to write unit tests against any code with a complex conditional logic
Detailed description of Strategy
Factory method
Factory method is also designed to be used in a complex conditional logic, but its usage is different from the usage of strategy.
Factory method allows you to generate any object of a particular type and, just like with strategy, you can decide on the exact implementation of the factory method based on conditions. However, there is one subtle, but significant, difference.
Strategy is used for executing a particular behavior or returning a short-lived simple data object, while factory method is used for generating a long-lived object that can execute its own logic outside of the factory method.
For example, let’s imagine that you have two databases – the main database and the archive database. They both store data in exactly the same format.
If you would need to decide which database to return the data from at the request time, you would use strategy. For example, a Boolean value that determines whether or not get the data from the archive is defined as a part of the request. And then you would select a strategy implementation depending on whether that value is set to true or false.
If true, you would use the implementation that gets the data from the archive database. If false, you would get the implementation that retrieves the data from the main database. But whichever database the data comes from, it is represented by exactly the same class in the code.
Now, imagine that you need to decide whether or not to use the archive database at config time. This way, you would have an abstraction that represents a database connection. When you launch the application, a factory method will assign the representation of either the main or the archive database to this abstraction depending on the config value. After that, any request will retrieve the data from whichever database was set up by this logic when the application was first launched.
Abstract factory
Because abstract factory is nothing other than a collection of related factory methods, it is applicable in the same way as factory method is, but only if you need to obtain a group of related objects rather than a single object.
Problem 11 – you have a high number of objects that need to be able to communicate with each other
Description of the problem
Imagine that you have a container object that contains other objects of various types. To make it clearer, imagine that the container object is a background of a user interface, while other objects are the components of it, such as text boxes, buttons, labels, etc.
There are certain events that certain objects need to emit that should be able to affect other objects. For example, clicking a particular button should be able to change a text on specific labels.
The last thing you would want to do in this situation is connect the components directly to each other. If you do that, your code will become excessively complex. It’s especially true when you have many elements inside the placeholder and they need to be connected together in arbitrary many-to-many relationships.
Suitable design patterns
Mediator
Mediator is a class that acts as a communication medium between the objects when they don’t have a way of communicating with each other directly.
An analogy would be an air traffic control. Airplanes that take off and land at an airport don’t communicate directly with each other; however air traffic control sees them all and issues appropriate instructions to each of them based on what other airplanes are doing.
In the example with the user interface, the background layout itself may act as a mediator. Once any of the controls on it emits a specific type of event, the layout class will decide whether this event is something that any other element needs to be aware of and it will notify that element accordingly.
So, none of the elements care about what happens after the event has been emitted. Deciding what to do with the event is a sole responsibility of a single mediator class. And if any other elements are affected, the mediator will issue instructions to them accordingly.
Why would you use Mediator
- The sole responsibility of facilitating communication between different objects is taken up by a single class
- Individual components are much easier to reuse
- Open-closed principle is easy to enforce
Detailed description of Mediator
Observer
Observer design pattern utilizes the concept of publishing and subscribing. Basically, any elements that emit a specific events are publishers and any elements that need to react to the event are subscribers.
So, if you want a specific object to be affected by specific event types or events with specific data values, you can subscribe that object to those events. If you no longer need to get that object to react to those events, you can unsubscribe.
And an object doesn’t have to be restricted to being either a publisher or a subscriber. It can be both. Likewise, an object can be a publisher and/or a subscriber for more than one event type.
Why would you use Observer
- You can easily establish relationships between objects at runtime
- Easy to enforce open-closed principle
- You can implement it across application boundaries
Detailed description of Observer
Problem 12 – you need a piece of logic that includes multiple stages of processing
Description of the problem
Imagine that you need to implement a logic that requires multiple stages of processing, possibly involving conditional logic.
One example of this would be a validation of HTTP request. First, you may want to see whether the incoming request matches any allowed paths in your application. Then, you may want to check whether the user is authenticated. After that, you may want to check whether the user is allowed to access the particular resource that the request was made for. And so on.
In this situation, you may want to short-circuit this flow as soon as you encounter a condition that wouldn’t allow the request to proceed any further. For example, if the request was made to a path that doesn’t exist, there is no point in checking the user’s credentials. Returning 404 page would be sufficient.
Suitable design patterns
Chain of Responsibility
This design pattern was specifically developed to deal with this problem.
Basically, your logic is arranged into a chain of individual components. Each component has a condition that decides whether to move on to the next component or short-circuit the logic then and there.
A good example of this would be an ASP.NET Core middleware pipeline which was designed specifically for the request validation that was described in the example above.
Why would you use Chain of Responsibility
- You can control order of multi-stage processing
- You can stop the process at any time if continuing doesn’t make sense any longer
- Each component in the chain is responsible for a specific stage of processing, so single responsibility principle is easy to enforce
Detailed description of Chain of Responsibility
Chain of Responsibility on Source Making
Chain of Responsibility on Refactoring Guru
Builder
Although it’s not designed for the specific request validation example outlined in the problem description, builder is suitable for other types of situations where you need to execute multiple processing stages.
The whole purpose behind builder is to allow you to build some sort of object step-by-step. So, if you put a builder implementation via a multi-stage conditional logic, you would end up with a different end product for each unique combination of conditions.
Problem 13 – you need to standardize requests to your system
Description of the problem
Some internal components of your system need to accept requests with instructions to do some actions.
Over time, the structure of the requests is becoming more and more complicated. For example, there may be different objects in your system that end up executing a very similar action, while having a completely different sets of inputs.
This may start causing issues in your code by making it less readable. For example, if a different object types end up executing the same action, you may put this action into a base class that all of these objects inherit from. But what if those objects are totally different, so having them inheriting from the same base type wouldn’t be appropriate? Also, if you have a large variety of such objects, you may end up with a lot of base classes.
So, your goal is to standardize your requests.
Suitable design patterns
Command
Command is a design pattern where the request is already embedded in the class that executes a particular action. This class is known as a command and it only contains a single method, which is usually called execute().
So, none of the objects will be responsible for generating the request, Once you create a command, it can be executed from any object. This leaves the command object with the sole responsibility of executing the action. Otherwise, all the calling objects need to do is call its execute() method.
Usually, execute() method comes with no parameters (perhaps, except for a cancellation token). But you can still populate the command with some unique values by passing those into its constructor when the command is created.
Why would you use Command
- Separating the request from the objects making them, which enforces single responsibility principle
- Standardizing instructions across your application
- Ability to implement undo/redo actions
- Ability to assemble simple instructions into complex ones
- Easy to schedule instructions
Detailed description of Command
Problem 14 – you need to be able to undo actions that have been applied
Description of the problem
Your software needs to be able to include undo functionality, which, these days, is present in most user interfaces that allow you to edit content.
This is a problem that UI developers were required to deal with for decades, and, as such, it can be solved by a number of standardized design patterns.
Suitable design patterns
Memento
Memento is a design pattern that was intended specifically to deal with this problem.
Memento is a name of an object that internally stores a sequence of snapshots. But it doesn’t reveal those details to the outside world. The only accessible endpoints that the memento objects would have would be related to the functionality that the originator class, such as an editor, would require. These may include passing a new snapshot into the memento, restoring old snapshots, etc.
Whenever a change is made in a specific object, a new snapshot of this object is created and it’s sent to the memento object, which appends it to its internal sequence of other snapshots. Then, if needed, the state of the originator can be restored from the history inside the memento.
Why would you use Memento
- Allows to store a full history of changes, so any of the snapshots can be restored easily
- Object oriented encapsulation is used well
Detailed description of Memento
State
Sate design pattern can be used in conjunction with memento. In this context, you can think of state as a snapshot that is saved into history and can be restored.
But other than that, state is a design pattern that makes an object change its behavior when it’s internal state changes.
For example, think of your mobile phone. If your phone is in locked state, a particular button would unlock it. However, when the phone is in an unlocked state, the behavior of the same button would be different. Perhaps, it would take you to the homepage.
This design pattern can also include state transition logic, which would be able undo and redo actions.
Why would use state
- Separating object behaviors from the object, which would enforce single responsibility principle
- Allows you to implement a state transition logic
- Allows you to introduce new behaviors to an object easily without violating open-closed principle
Detailed description of State
Command
As it has been mentioned previously, command design pattern allows you to enable undo and redo actions. However, if you want to be able to apply such actions on a long history of changes, you would still need to use command in conjunction with state, memento or both.
Problem 15 – you need to be able to traverse elements within a collection without having to know its underlying structure
Description of the problem
You have a fairly complex data structure due to various constraints that you have to overcome. Perhaps, you need to arrange the data into a binary search tree to enable an efficient search algorithm. Or perhaps it’s a linked list, as each item in the collection needs to know about the next item.
In any case, the client class that will be using your library would not care about what algorithm you used and how your data is structured. All it cares about is that it can work with the data in your collection.
Suitable design patterns
Iterator
Iterator is a design pattern that hides implementation details of a collection-manipulating algorithm and only exposes some basic methods that enable any external object to work with the collection, such as moveNext() and hasMore().
So, as far as your client is concerned, the collection you are dealing with consists of sequential flat data, just like an array would be. However, internally, the data structure can be anything but.
These days, you will rarely have to implement iterator yourself, as core system libraries in all major programming languages already have a whole range of collection types that implement iterators.
Why would you use Iterator
- Abstracts away complex implementation details of collection management
- Simplifies the view of the collection to the client
Detailed description of Iterator
Problem 16 – you need to define several related algorithms
Description of the problem
Imagine that you need to create a family of related algorithms. Each of them will have the same parameter types, the same output object type, but would be comprised of completely different logic.
You can just create many similar methods, but design patterns allow you to achieve your goal in a better way.
Suitable design patterns
Template Method
Template method is, perhaps, the simplest way of achieving the goal of defining a family of related algorithms.
In the nutshell, template method is just a fairly standard usage of a standard object oriented feature of inheritance. You define either a skeleton method without implementation or a method with a default algorithm implementation in your base class. And then, you just inherit from this class and modify the algorithm steps as needed.
There is a caveat though. This design patter is only suitable for very similar algorithms. Otherwise, if you alter an algorithm behavior significantly, you may be violating Liskov substitution principle.
Why would use use Template Method
- The easiest way of creating several related algorithms
- You can get the clients to only override specific parts of the default algorithm
- You can store a bulk of your code in the base class
Detailed description of Template Method
Template Method on Source Making
Template Method on Refactoring Guru
Visitor
Visitor is a design pattern that allows you to separate algorithms from the objects they operate on. So, you can add new behavior to an object without having to change the object itself.
Visitor is a class that operates on an object but a separate from it. Therefore, because your visitor is separate from your object, you can define a number of different visitors if you want to apply different algorithms to your object.
In order for a visitor to work, a visitor class needs to be able to “visit” the object. And then it can just call and modify modify the values of any accessible members of the objects. The only components that the visitor will not have access to are private variables and methods.
Why would you want to use Visitor
- Separating algorithms from the objects they operate on, which enforces single responsibility principle
- Can add any new behavior to an object without having to change the object
- Can have different sets of behaviors that can be applied to objects
- Visitor class can accumulate a lot of useful information about an object by visiting it
Detailed description of Visitor
State
As it has already mentioned, state design pattern alters object’s behavior based on it’s internal state. Therefore, if you want introduce a new behavior to an object, you can create new states for it.
In this context, state would, in a way, be similar to visitor. The major difference, however, is that state object would reside inside the object, while visitor would come from outside and would act almost like a wrapper around the object.
Strategy
Strategy was intended to be used inside a specific set of conditional logic, so, by definition, it is also a way of defining a series of related algorithms.
After all, all strategy objects within the same set will implement exactly the same interface, making this design pattern a suitable solution for this specific problem.
Wrapping up
As you could see from the examples above, some of the design patterns are suitable for solving more than one type of a problem.
Also, I haven’t covered every single design pattern that has ever been defined. I have only covered the main ones that have been originally defined by Gang of Four in their book, which is universally considered to be the definitive guide to design patterns.
Of course, the list of the problems outlined in this article that design patterns can solve is not exhaustive either. I have just listed the most common ones.
If you think that there are any other problem types that are as important as the ones described above, your input will always be appreciated. Let me know in the comments what you think.
This article is not a one stop shop for learning design patterns. It is merely an introduction to them.
Eventually, as an experienced developer, you would need to gain a more in-depth knowledge of design patterns, so you will not only understand them conceptually, but will also be able to apply them intuitively. And there is no better place to learn them than the original canonical book written by Gang of Four – Design patterns : elements of reusable object-oriented software.
This book, along with Clean Code, is something that every software developer who is striving for excellence must have in their library. Both of these famous books have stood the test of time and are highly regarded by well-known industry influencers, such as Martin Fowler.





